Somewhat strangely, you might think, the BBC doesn’t publish persistent webpages for most its programmes. Or rather it didn’t, because today we’ve launched comprehensive programme support (in beta). So now if you go to bbc.co.uk/programmes you will now find an episode page for all our programmes – whether on radio or TV.
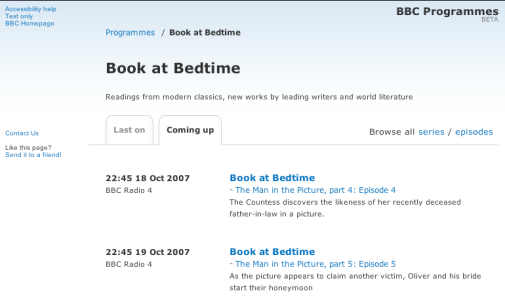
Unlike the existing What’s On service, which publishes a page for every broadcast, with bbc.co.uk/programmes, we are publishing a page for every episode (with broadcast information), programme or series. In other words, rather than a the specific broadcast instance we are publishing a page for the cultural entity. A page for every episode rather than every individual broadcast is cool. Its cool because no matter how many times the programme is broadcast there remains just one page to represent that programme. This helps people find the programme because it helps maximize Google Juice – because all references link to the same URL. It also means that we can add more information to the same page over time and create context around that episode.
If instead of creating a page for each episode we created a page for every broadcast not only would we dilute the Google Juice we would also dilute the information about that programme. Users would be swamped with dozens of versions of broadly the same page, each with slightly different bits of information or different links. This makes it harder to find what you want and when you do find it the page is less valuable because it contains less information.
Publishing a page for every episode is all well and good, but its not the whole story, its also important to be able to create context around programme pages. What does this mean? Well, for starters we are categorizing programmes by genre and format and letting users browse by these categories, we are also grouping episodes into series, and programme. And over time we will add more information and additional links to supporting webpages.
We also want to help other people create context around our programmes so we have implemented a few features to support this too (although we aren’t including all these in this initial release). First up relevant pages are microformatted with hCalendar which makes it easier for the data on the webpages to be processed with software. And in the near future we’ll be publishing the data in different formats – RSS, Atom and HTML for starters, and iCal and JSON after that. And finally the URLs for all this will also be persistent – the resource will always be available and the URL to that resource will remain the same.
Providing persistent URLs is clearly a good thing – it means people can link to a page and know it will remain available and search engines work better – but building a system to deliver persistent URLs has some important implications. What have we chosen to do? Well here are some URLs:
- bbc.co.uk/programmes/genres/music
- bbc.co.uk/programmes/formats/documentaries
- bbc.co.uk/programmes/b006qtlx
And some future URLs:
- bbc.co.uk/radio4/programmes/
- bbc.co.uk/radio4/programmes/genres/news
- bbc.co.uk/programmes/tags
- bbc.co.uk/radio4/programmes/tags
- bbc.co.uk/programmes/tags/japan
- bbc.co.uk/radio4/programmes/schedule/fm
- bbc.co.uk/radio4/programmes/schedule/fm/2007
- bbc.co.uk/radio4/programmes/schedule/fm/2007/10
- bbc.co.uk/radio4/programmes/schedule/fm/2007/10/12
- bbc.co.uk/radio4/programmes/schedule/fm/2007/week40
- bbc.co.uk/programmes/b006qtlx.rss
- bbc.co.uk/programmes/b006qtlx.atom
The most obvious thing to note is that we haven’t included the programme title, broadcast date, Programme Brand (e.g. Heroes) nor channel (e.g. Radio 1 or BBC2) in the URL for our primary objects because all these things can change and its never a good idea to reflect your organisational structure in your URLs. For example, programmes are repeated on different channels – especially in the era of multi channel TV and P2PTV and programmes can start off on one channel before being ‘promoted’ to another (e.g. Little Britain).
So instead the individual objects (episodes, programmes and series) are identified using an eight digit, alpha numeric key. And this doesn’t ever need to change – not when we change the underlying technology, nor when we add more information, rebroadcast the programme, or decide to reorganise. However, the URLs for the aggregation pages (e.g. …/programmes/genre/music) are human readable and hackable, they support wombling.
UPDATE (2007.12.17)
Some more information on new features: tags and radio player, and iPlayer embedded video.
