Jamie’s recent post about his work on the design of BBC’s /programmes service highlights an important trend in the design of modern web products. It’s all about the resource and its URL.

Web site design use to be focused on the page and the sitemap – we assumed users would visit a site and browse around a bit while they were there – sites therefore wrapped their content in heavy branding and optimised their navigation around the ‘left hand nav’.
This sort of made sense if, as a publisher, you’re dealing with a small number of pages, your paradigm for web publishing is the same as print publishing and your technology is limited to static files. However, it does force users into navigating in a ‘wagon wheel strategy’ i.e. they would read something and then navigate up to a top level index page (e.g. news, programmes, a-z &c.) to find something else of interest before navigating out again to a resource.
Site owners effectively thought of their sites as silos – a self contained object, a web of pages, with a handful of doors (links) in and out – well even if they didn’t think of them as silos they sure treated them as such. But as Tom Coates puts it Web 2.0 is about moving from a “web of pages to a web of data“:
A web of data sources, services for exploring and manipulating data, and ways that users can connect them together.
This has some important implications for the design of web sites. Users expect to be able to navigate directly from resource to resource. From concept to concept. Look at the YouTube design – right there on the right are links to other related videos and the top level navigation is light weight and focused around aggregations or list views.
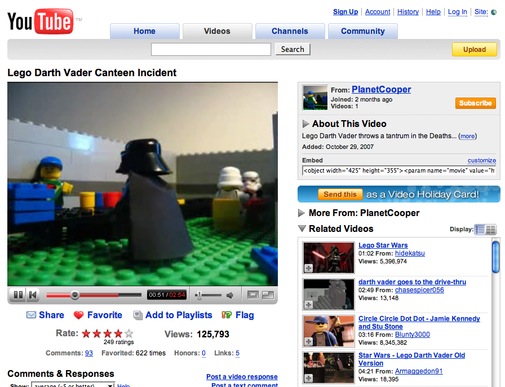
In other words web 2.0 sites have two main classes of page: primary objects or resources and aggregation views which give their users multiple routes into the same resource. And that resource is located at a single URL. That last point might seem painfully self evident: ‘one resource = one URL’ but either its not that obvious or its difficult to achieve.
Wikipedia are the masters of this – they work to ensure that they only have one entry per concept – this means that they have one URL per concept. And that’s a lot better, if harder to achieve, than one URL per resource. On Wikipedia an entry will be moved, merged or split to ensure that it only deals with one concept. But even if your resource deals with more than one concept, it should only be found at one (persistent) URL so that search engines can index it properly (so people can find it); so people can link to it and; so third party applications can be integrated with it. Simon Willison explains why, although people may well be able to discern that two URLs probably point to the same thing, machines can’t.
Once you have a single resource at a single persistent URL you can start to do some interesting things. You can make that resource available in a variety of different formats each optimised for different uses: HTML for web browsers, XHTML MB or WML for mobile, JSON for Ajax applications etc. You can start to expose your data to other web applications and then you can start to benefit from the network effect.
One consequence of a network effect is that the purchase of a good by one individual indirectly benefits others who own the good — for example by purchasing a telephone a person makes other telephones more useful.
By making your site and its data available in this way means that others will be able to link to your resources to help give context to their content. And if you’ve done your job well they won’t even need to manually ‘link’ to it – if you happen to be using a common set of identifiers and vocabularies then web applications can do a lot of the work for you.
If however, you start off by thinking about web pages, site maps, left hand navigations and visual design you will very quickly photoshop yourself into a corner. You will find it difficult to create a web of data instead you will end up with a bag of pages, others won’t be able to integrate with your data and your relevance on the web will fall or fail to start.
And if you are after a case study of what to do – you should have a look at Matt’s presentation at FOWA on the development of Dopplr.
