What is an ontology? Well if you Google for it you’ll find lots of references to “an explicit specification of a conceptualization“. More usefully an ontology is a way of formally describing what something is and how it relates to other things.

Over the last few years their popularity has waxed and wained: Yahoo tried to categorize web sites into predefined hierarchical categories – but as Clay Shirky points out that didn’t work so well because “there is no shelf“:
Yahoo, faced with the possibility that they could organize things with no physical constraints, added the shelf back. They couldn’t imagine organization without the constraints of the shelf, so they added it back. It is perfectly possible for any number of links to be in any number of places in a hierarchy, or in many hierarchies, or in no hierarchy at all. But Yahoo decided to privilege one way of organizing links over all others, because they wanted to make assertions about what is “real.” […]
One reason Google was adopted so quickly when it came along is that Google understood there is no shelf, and that there is no file system. Google can decide what goes with what after hearing from the user, rather than trying to predict in advance what it is you need to know.
In other words rather than having a site located in one predefined location within a classification scheme you have linked resources. Obvious huh? But in that case why does anyone bother with trying to define a classification system? Because there are situations where having a classification scheme does make sense. Clay suggests these situation include the following:
- Small corpus
- Formal categories
- Stable entities
- Restricted entities
- Clear edges
The whole of the internet doesn’t fit these criteria, which is why Yahoo had problems – but somethings do – and one that does are TV and radio programmes, not at the subject matter level but at a meta level, at a level of how programmes are structured: episodes, series, broadcasts and the like.
A few years ago the Audio and Music part of the BBC, where I now work, started to look at how to model programmes – Tom Coates post ‘the age of pointing at things‘ describes much of this early work. Since then we’ve significantly re engineered the underlying technology and rolled it out for all BBC programmes.
As I discussed previously the idea behind BBC Programmes is to ensure that every programme brand, series and episode broadcast by the BBC has a permanent, findable web presence. The Programmes Ontology was developed by Yves, Michael, Patrick and Nick to expose this data following the Linked Data approach, enabling the interchange of programme information on the Semantic Web. This then is the current ontology for programmes:
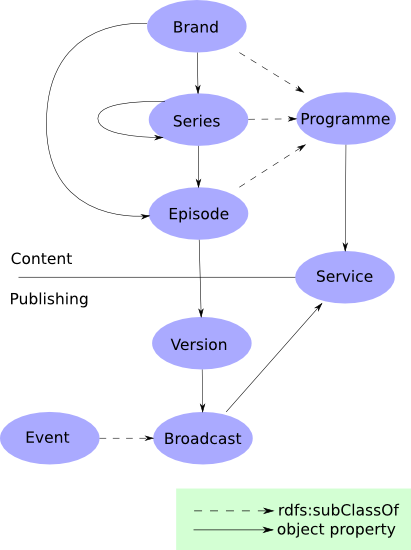
The ontology provides identifiers for concepts such as brand, series and episode and is divided in two main parts. Firstly, it describes categorical information about programmes, and the relations between those categories. For example, it allows the description of a programme brand, a series constituting it and the episodes in that series. And secondly it describes the services and broadcast events.
Internally we’ve used this ontology and a D2R server to map the underlying relational databases to RDF through SPARQL which resulted in over 5 million RDF triples accessible via multiple views (brand, series or episode) in addition to direct queries via the SPARQL interface.
SPARQL is a bit like SQL for RDF and the so provides an interface that allows access to the data in ways that would be difficult to achieve via the Programmes web interface. In addition SPARQL can be used to connect and combine data sources external to the BBC, such as DBpedia, which can be used to contextualise the programmes data with information not held within our dataset e.g. the date and place of birth of cast members.
Finally to facilitate its uptake we have released the ontology under a Creative Commons license. So if you need to model TV or Radio programmes please feel free to use it.
Photo: The British Library, by Steve Cadman. Used under licence.
